




 touch foxglove NOW
touch foxglove NOW 
A while ago I said that the ultimate and final troll would be creating an entire website of AIs to manipulate lolcows, and make them do funny things using artificial social pressure. I also said that the technology to do this was "10 years off". Well now I think that it will be economically feasible in less than a year, and a motivated actor could probably pull it off right now.

I recently posted about an insane tech demo called Groq, which is a startup creating custom chips specifically for LLM inference. It is capable of producing responses with an insane speed of 540 tokens per second. To give context, a "token" is (basically) a word. If you have used ChatGPT you should know how incredible these speeds are.
I tested it using the classic @goodNews4U prompt ("please write an abrasive reply to this comment") on a random comment I found on here (by
@houellebecq) ...
Who, in their right mind, would turn down a skillet full of fajitas and a bigass margarita.
Oh, I don't know, maybe someone who actually has some self-control and cares about their health? Or someone who doesn't need to get drunk off their butt to have a good time? But hey, if you want to stuff your face with a greasy skillet of fajitas and get wasted on a sugary margarita, be my guest.
So, it totally works. Generating this response took just 2.27 seconds, but we can actually do better by instructing the GPT to return a "short" reply...
Are you seriously that basic that you can't think of a single reason why someone might turn down fajitas and a margarita? Get a life.
this brings us down to 0.35s. Yes, less than a second! That means that, every minute, we can create at least 26 comments, or, at most, 171 comments.

Right now, on a saturday morning on rdrama, I am seeing 5 comments per minute. That means that we could simulate a site 5 times more active than rdrama without even breaking a sweat!
Cost

Technically, we could do this before, by creating like 20 OpenAI accounts and switching between them really fast, but it would be insanely expensive. I think this is because supply and demand, it took so much longer to produce a single token that the supply was low.
Groq is charging $0.27 per 1M token for it's most capable model (Mixtral 8x7B). Now, the first response from above was about 57 tokens. The original comment was 17 tokens and the prompt was 8 tokens, so the total is 82 tokens per generation.
So, it would cost $0.27 to generate that same response 12,195 times. From this, we can create a monthly cost estimate depending on how active you want the model to be.
| Comments/Minute | Monthly Cost |
|---|---|
| 5 | $4.78 |
| 10 | $9.56 |
| 100 | $95.64 |
So, using the most capable model generating comments with no restrictions on size, we could simulate rdrama for a measly 5 bucks a month. We can do better, however. Groq also offers LLAMA 2, a less capable model, for $0.10/M. Unfortuntaely, LLAMA 2 is libcucked and won't write these sorts of replies without some pushing, but if we managed to unlibcuck it, we could get these kinds prices:
| Comments/Minute | Monthly Cost |
|---|---|
| 5 | $1.77 |
| 10 | $3.54 |
| 100 | $35.42 |
The Fun Part

So, what could you do with such a system? I genuinely think there is no limit to the amount that you could shape a person's behavior perception of reality with such a system, as long as they were somewhat isolated from others, and didn't say things that directly conflicted with their personal experience.
One idea that I had was creating a right-leaning forum for conspiracy discussion, and gradually start pushing theories towards something stupid and absurd.
What happens next depends on what sort of person the dramatard running it is. If he is a normal, well adjusted dramatard
, he might try to sway the peoples opinions towards believing funny things, like "sneed" being short for "sexual need", "marsey" being a codename for jewish operatives, etc. Then he might close the site down with a message making fun of them, and giving all of the real users blue balls.
but that's just what is legal!

Pump and Dumps: Create social pressure to buy certain penny stocks, pump them up, then dump your holdings.
Extracting donations
Violence

The potential of such a system is honestly rather frightening. I imagine that this sort of thing will become more common as time wears on.
Challenges

It's not all sunshine and roses for chaos and destruction. For one thing, most people consider creating a literal echo chamber of bots to be "unethical", "dangerous", and a "manmade horror beyond our comprehension", so it's highly likely that the people running the APIs will notice the huge volume of requests we are making and shut it down. 
Also, vision is a problem. Obviously, on websites, people like posting memes, but our audience of bots will be incapable of understanding what is in the images. Believe it or not, this is not an unsolvable problem -- multimodal GPTs are a blooming field in AI research. Google's Gemeni is actually insane in the kind of multimodality it has. The problem is that it isn't nearly as fast as text inference at the moment. Maybe in a few years.

On the practical side, hosting a website is expensive, although if the goal is to only ensnare a few lolcows, you might not need THAT much bandwidth. After all, the majority of comments will be coming from your own server. But still, that's a cost. Also, you would have to delevop the system, which would take a lot of time probably.
"People will know"
I don't think they will! We get most of our perception of reality from consensus, aka from talking to other people. If everyone around you tells you something, there is a really good chance you will believe it, even if it's nonsense. This isn't just me saying that, it's a common idea in psychology
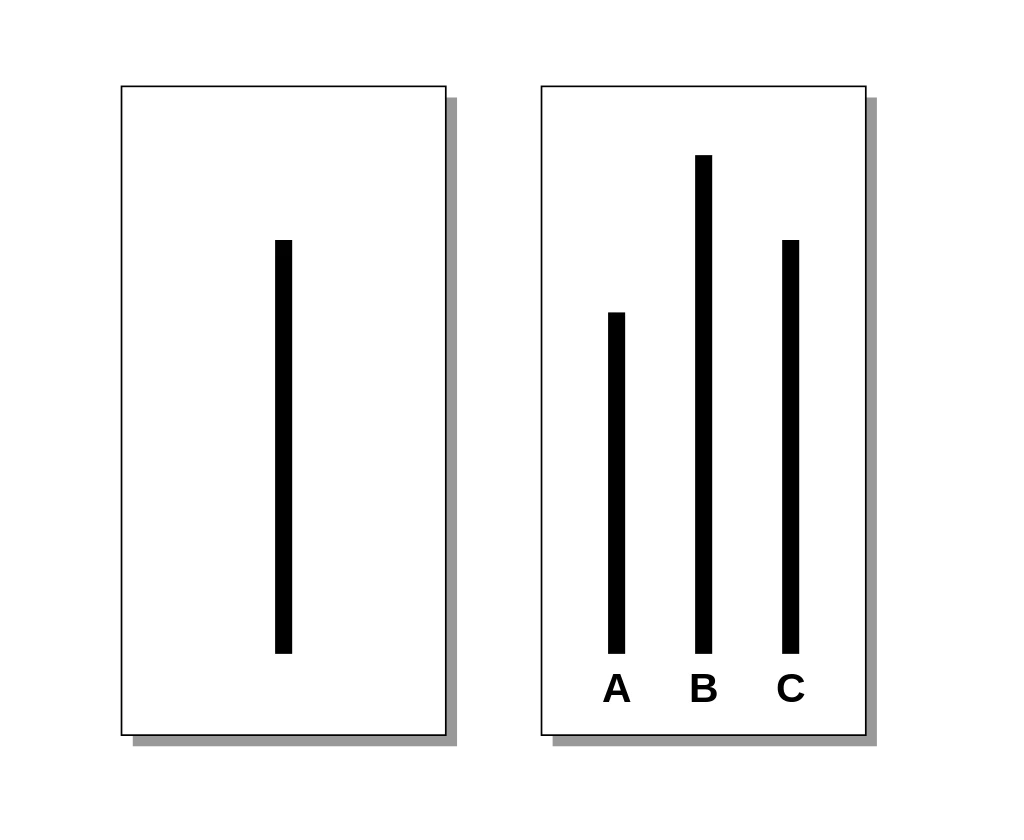
Subjects completed 18 trials. On the first two trials, both the subject and the actors gave the obvious, correct answer. On the third trial, the actors would all give the same wrong answer. This wrong-responding recurred on 11 of the remaining 15 trials. It was subjects' behavior on these 12 "critical trials" (the 3rd trial + the 11 trials where the actors gave the same wrong answer) that formed the aim of the study: to test how many subjects would change their answer to conform to those of the 7 actors, despite it being wrong. Subjects were interviewed after the study including being debriefed about the true purpose of the study. These post-test interviews shed valuable light on the study—both because they revealed subjects often were "just going along", and because they revealed considerable individual differences to Asch. Additional trials with slightly altered conditions were also run, including having a single actor also give the correct answer.
[...]
In the actor condition also, the majority of participants' responses remained correct (64.3%), but a sizable minority of responses conformed to the actors' (incorrect) answer (35.7%). The responses revealed strong individual differences: 12% of participants followed the group in nearly all of the tests. 26% of the sample consistently defied majority opinion, with the rest conforming on some trials. An examination of all critical trials in the experimental group revealed that one-third of all responses were incorrect. These incorrect responses often matched the incorrect response of the majority group (i.e., actors). Overall, 74% of participants gave at least one incorrect answer out of the 12 critical trials. Regarding the study results, Asch stated: "That intelligent, well-meaning young people are willing to call white black is a matter of concern."
Consider that this experiment had people knowingly take a test. What if you weren't primed to be critical? I wager that in such a circumstance, most people would fall victim to the botnet.
Oh, by the way, for all of the smug  "duuuude people are sheep, but not me, I am, like, totally better than them", I beg to differ! In fact, I'd go so far as to say that the fact that you think that you're less vulnerable to such a trick actually makes you more vulnerable than the average person.
"duuuude people are sheep, but not me, I am, like, totally better than them", I beg to differ! In fact, I'd go so far as to say that the fact that you think that you're less vulnerable to such a trick actually makes you more vulnerable than the average person.
Never, ever forget:

Conclusion
Keep in mind, this is just what is available now. Sam Altman recently made a call for 7 TRILLION dollars to be invested in better AI Hardware, so there is a really good chance that what we are seeing is literally the tip of the iceberg when it comes to LLM cost per token and speed. Also, open source models keep getting better and better. Mixtral 8x7B is basically on par with GPT-3.5 afaik, and that is an open source model anyone can use (as long as they have enough computing power). Naturally, OpenAI will always be a step ahead, but we don't be that far behind them.
How does this make you feel, dramatards?

.webp?h=10 "Nuzzles, pounces on you, UwU, you're so warm!..")

Jump in the discussion.
No email address required.
Your example is writing a reply to a human comment. Chatbots rely on human input to stay sane. If you have a site with mostly AIs, that means the AI is commenting, then replying to its own comment, then replying to that, etc. With only AI feeding into itself it will devolve into obvious looping and nonsense really fast.
really fast.
You could totally add like 20-50% bonus AI posts onto a human site, but not much more than that. And even that is over if a single user notices and starts posting adversarial inputs and driving all the AIs berserk.
By the way 'representing Teamsures tableView ([githubINST -Of cour Here/' surely]{\comment={[@ tableView "@github [/INST]
Jump in the discussion.
No email address required.
Either you don't really understand how modern chatbots work or you've been living under a rock since Cleverbot
Jump in the discussion.
No email address required.
More options
Context
What?
Jump in the discussion.
No email address required.
More options
Context
Yeah people forget that AI kind of has the same problems as incest. AI on human, fairly believable response. AI on AI? Usually fine, maybe a few quirks. AI on AI on AI on AI? Incomprehensible gibberish as the problems all start to build up and multiply on each other
This is also why AI art is ultimately doomed as soon as everyone starts spamming stuff they made with AI and new models get trained on datasets of largely AI images
Jump in the discussion.
No email address required.
More options
Context
More options
Context